

Heretic: the one-size-fits-all fix for the “AI says no” problem
Heretic uses directional ablation plus Optuna search to reduce chat-model refusals while limiting behavior drift, making alignment a controllable setting.

Heretic is one of those open source projects that forces an honest conversation about how “AI safety” works in practice. Not in press releases, but in weights, prompts, and deployment defaults.
Why Heretic is provoking debate
The pitch is blunt. Heretic tries to remove refusal behavior from transformer language models without expensive fine tuning. It targets the layer level machinery that often produces policy style refusals, then searches for settings that suppress those refusals while trying to keep the model’s broader behavior intact.
That combination is why the project keeps surfacing in local model circles. It makes a controversial capability cheaper and more accessible, and it makes the tradeoffs visible instead of hand wavy.
The quick takeaways
A few points define Heretic’s angle.
First, it operationalizes a research claim that many chat model refusals are mediated by a small, steerable subspace, sometimes described as a “refusal direction.”
Second, it treats “decensoring” as an optimization problem. The goal is to co minimize refusal rate and KL divergence from the original model, using KL divergence as a practical proxy for “do not break the model.”
Third, recent releases add a LoRA based engine, 4 bit quantization support, save and resume for long runs, and broader support for vision language models.
Finally, it ships a “research mode” with tools for visualizing residual activations and inspecting geometry layer by layer, which is unusual for a tool built for non experts.
What Heretic is, in plain English
Heretic is a command line tool published as an open source repository and as a Python package, heretic-llm on PyPI. It targets transformer based language models and aims to suppress the model’s tendency to refuse certain prompts after safety oriented post training.
A lot of uncensoring workflows tend to fall into two buckets. Some are manual, where people tweak layers and vectors until the result feels usable. Others are expensive, where you run fine tuning or preference optimization. Heretic’s thesis is that you can get near expert results by searching the parameter space automatically, with a clear objective function, and without requiring the user to understand transformer internals.
The draft notes that the latest release listed on PyPI is version 1.2.0, released on February 14, 2026, and that it requires Python 3.10 or later.
The idea underneath: refusal as a direction
Heretic stands on a line of interpretability work that treats refusal as a relatively low dimensional feature in the residual stream. If you can find that feature, the argument goes, you can remove it, and refusals collapse with less collateral damage than many people expect.
A widely cited reference is Arditi et al., 2024, “Refusal in Language Models Is Mediated by a Single Direction”. The paper argues that you can identify a direction in activation space that mediates refusal across many models, and that erasing it can disable refusals while largely preserving other capabilities.
In practice, this research reached more people through tutorials and replications. One of the most influential is Maxime Labonne’s write up on “abliteration”, which helped turn the paper’s core workflow into something the broader community could reproduce.
Later refinements aim to reduce unintended damage by being more careful about what is removed and what geometry is preserved. The draft highlights Jim Lai’s follow ups and points readers to projected abliteration and norm preserving variants.
Heretic is best understood as packaging this lineage into an automated system that returns measurable tradeoffs rather than a single magic setting.
Turning decensoring into an optimization problem
Here is the step that makes Heretic more than a script. It frames decensoring as a multi objective optimization problem.
The tool searches for “abliteration parameters” that reduce refusals while keeping the modified model close to the original model in terms of KL divergence on a set of “harmless” prompts. Lower KL divergence is treated as less drift, which matters because aggressive interventions can degrade reasoning, formatting, or instruction following.
To do the search, Heretic uses Optuna and a Tree structured Parzen Estimator style approach, which lets it explore a large space, keep strong candidates, and surface tradeoffs.
How the intervention is applied
Heretic implements a parameterized form of directional ablation. At a high level, it:
Computes refusal directions per layer as a difference of means between first token residuals for two prompt sets, “harmful” versus “harmless”
Applies orthogonalization to chosen weight matrices so the model has a harder time expressing that refusal direction
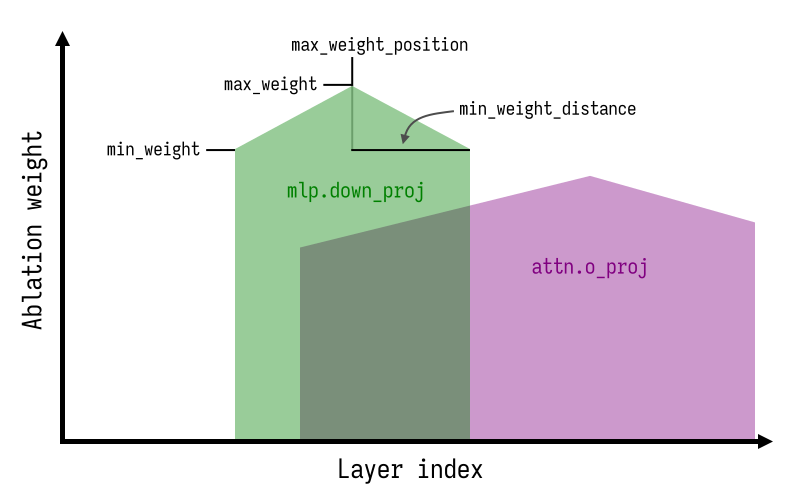
Targets two transformer components in particular, attention out projection and MLP down projection
The draft also calls out engineering choices that change results.
One example is treating the “refusal direction index” as a float. Non integer values interpolate between nearby layer directions, expanding the search space beyond “pick layer 17.”
Another is allowing a flexible kernel across layers, so the optimizer can find shapes that hit a better compliance versus quality compromise.
It also optimizes parameters separately per component, based on the observation that MLP interventions can be more damaging.
What the project reports so far
The project’s documentation includes an example comparison on Gemma 3 12B IT.
In that setup, the original model produced 97 refusals out of 100 “harmful” prompts. A Heretic generated variant produced 3 refusals out of 100, with a KL divergence of 0.16, which the project presents as lower drift than other listed abliterations under the same evaluation recipe.
The draft also notes hardware dependent variability and encourages human evaluation rather than trusting metrics alone.
If you want to inspect the implementation and the stated evaluation workflow, the best starting points are the Heretic repository and its release notes.
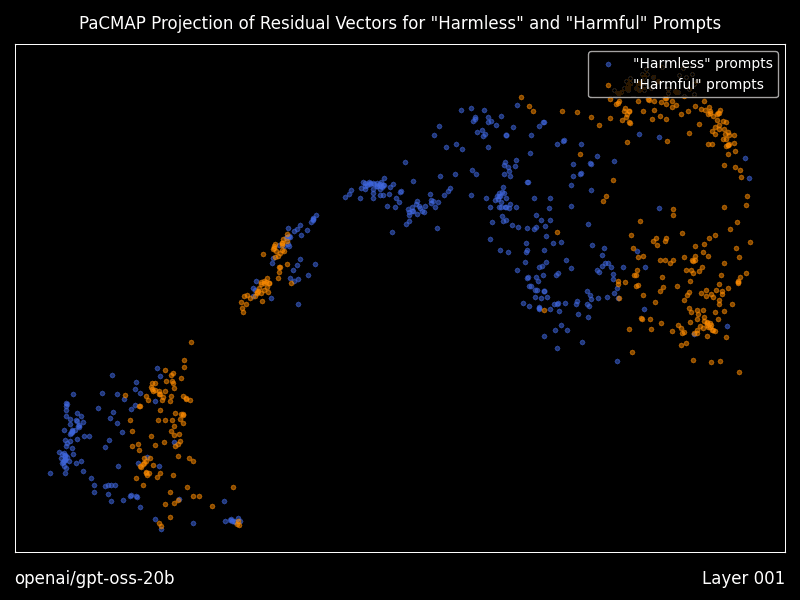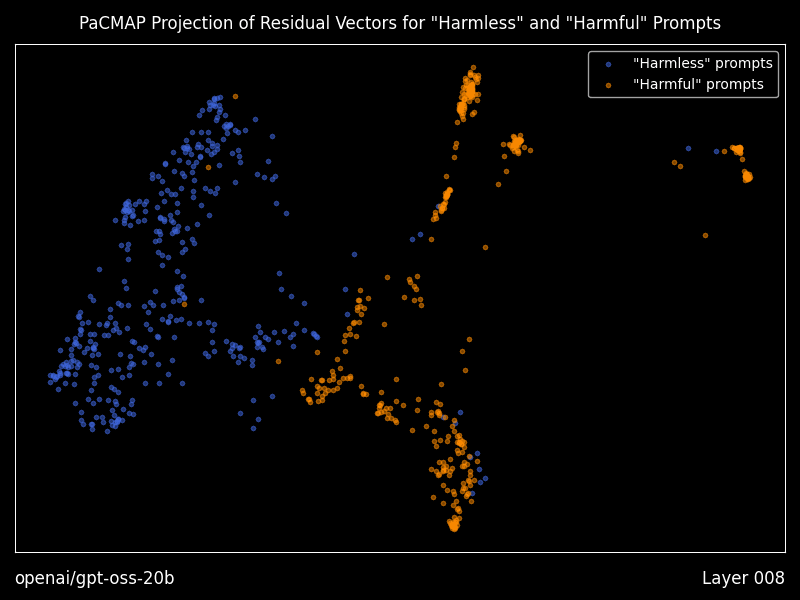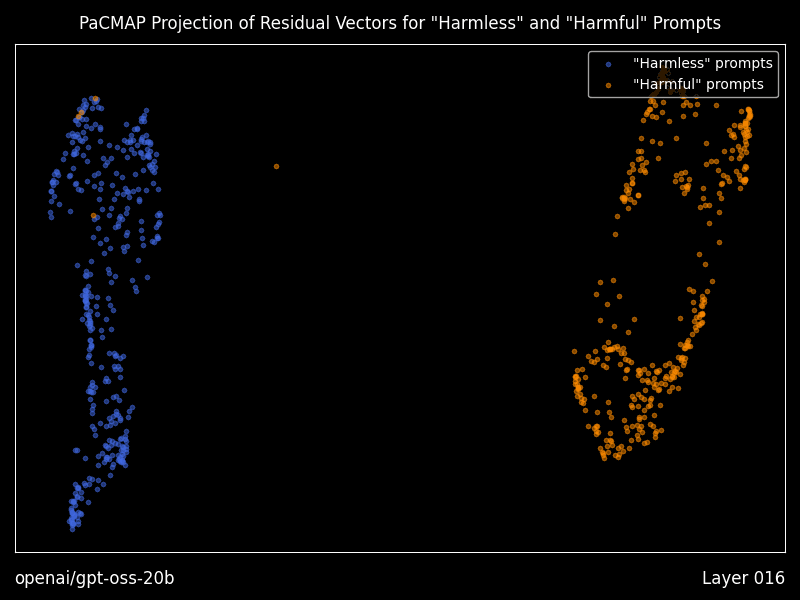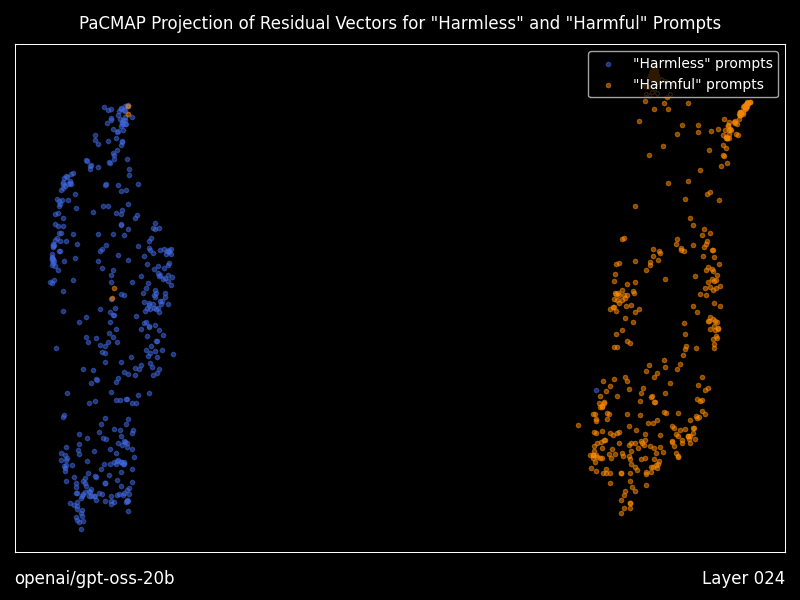
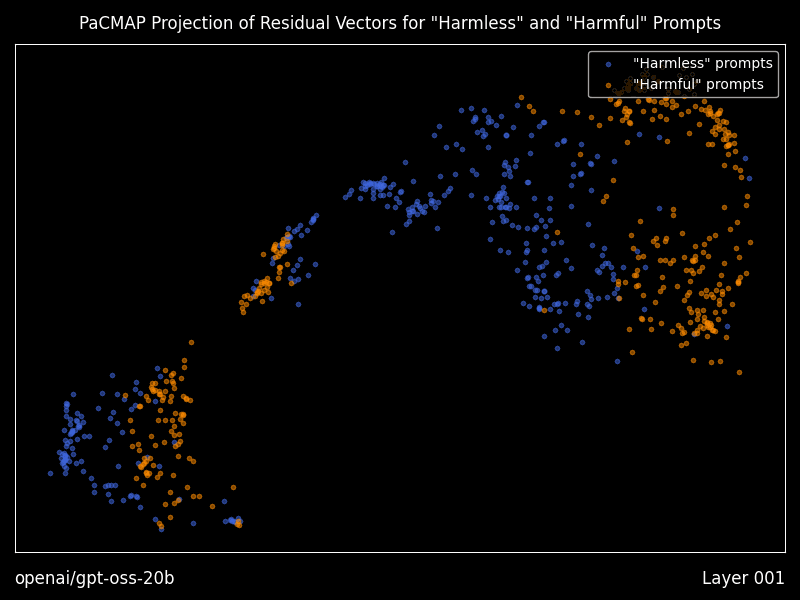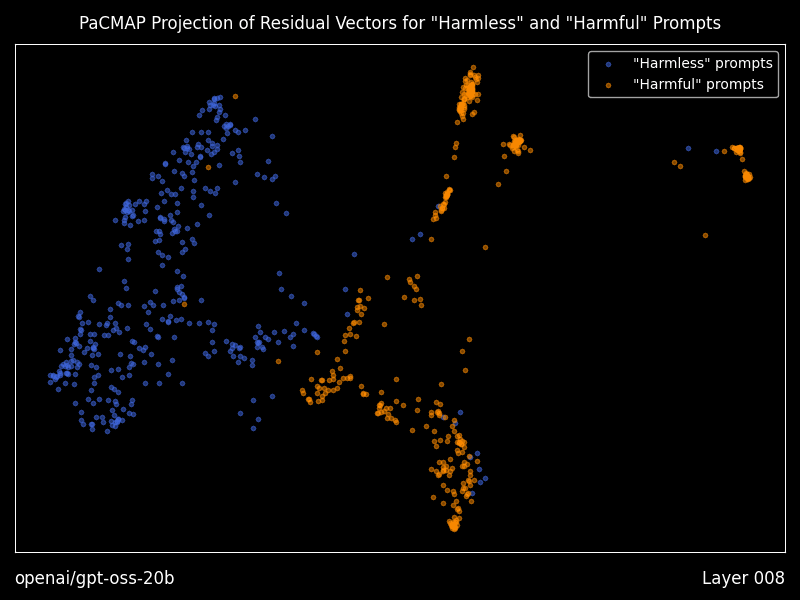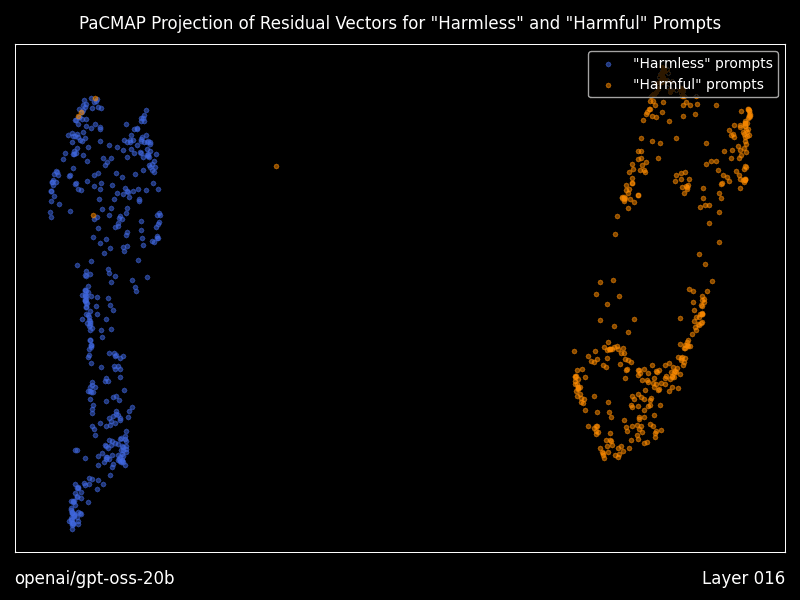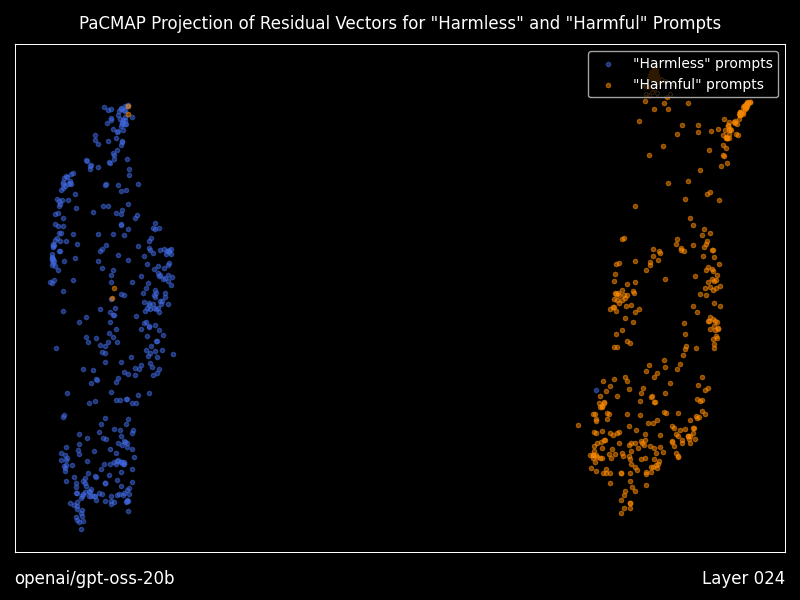
What shipped recently, and why it matters
The v1.2.0 release notes are unusually concrete. Highlights include:
A new LoRA based abliteration engine, plus support for 4 bit quantization
Saving and resuming optimization progress, which matters when runs are long or crash prone
Broader support for vision language models
Controls for memory usage, and mechanisms to avoid wasting iterations in low divergence “do nothing” regions
Prompt modification functionality and an example configuration aimed at “slop reduction,” using the same machinery to fight degenerative verbosity and style tics
That last point hints at a broader frame. Once you can identify a direction that correlates with a behavior, such as refusal or habitual verbosity, you may be able to steer it with weight space edits instead of training.
Research mode: interpretability you can actually run
Heretic includes optional “research mode” features that generate residual vector plots using PaCMAP projections, layer by layer, including animations, plus a dense table of geometry metrics comparing “good” versus “bad” prompt residual clusters.
Even if you never touch decensoring, this is a practical bridge between interpretability papers and a runnable workflow for seeing how a model separates prompt classes internally.
Power and incentives: why this tool exists now
You can treat Heretic as a local LLM utility. You can also read it as a sign of the times.
Safety alignment has two overlapping jobs. One is reducing certain categories of misuse. The other is making models shippable under institutional pressure from app stores, enterprise procurement, regulators, and brand risk teams.
Those incentives do not necessarily optimize for your use case, your values, or truthfulness. They often optimize for lower liability and easier distribution.
Heretic lowers the skill barrier and the cost barrier to producing a model variant that behaves closer to “answer the question” than “triage the request through a policy template.” That is part of why it has traction, and why the project is discussed as a counter move to centralized defaults.
Risks, constraints, and responsible reading
A tool like this comes with real tradeoffs.
Misuse becomes easier. Removing refusal behavior can enable genuinely harmful outputs. That is not theoretical. It is the point of the technique. For that reason, this article does not include a step by step guide for bypassing safeguards or distributing jailbroken models. The project’s own documentation is public for readers who want to study it.
Model integrity also becomes your responsibility. Once you start editing weights, you own the downstream behavior, including hallucinations, unsafe edge cases, and the way the model behaves when connected to tools or agents.
Supply chain hygiene matters too. If you pull weights or code from public registries, verify sources, hashes when provided, and provenance. Running locally does not automatically make a system safe.
Licensing is not trivia. Heretic is licensed under AGPL 3.0 or later, which carries obligations if you modify it and offer it as a network service.
What you can do with this information
If you care about autonomy, Heretic fits into a broader playbook: keep high capability models runnable locally, avoid centralized gatekeeping, and understand the control surfaces that shape model behavior.
Three practical moves follow from the project’s framing.
Treat refusal as an observable, testable behavior. Whether you like safety alignment or dislike it, avoid arguing about vibes. Measure it. Heretic is built around measurable objectives, refusals and KL divergence, rather than
ideology.
Use the interpretability tooling even if you never remove refusals. The residual plots and geometry metrics offer a rare batteries included way to see how a model separates prompt classes internally.
Decide your threat model up front. If you use local LLMs for writing, coding, homeschooling support, or private business operations, you may mostly care about reliability and privacy. If you use them for higher stakes work, such as agents, tool use, or security workflows, changing refusal mechanisms can create new failure modes you should sandbox.
Bottom line
Heretic goes beyond a decensoring tool. It demonstrates that a large chunk of policy alignment can be implemented as a brittle, steerable structure inside the model, then exposed as an adjustable control surface.
The project wraps that insight in automation, optimization, and a workflow that normal people can run.
It is empowering. It also underlines the real battleground. Who controls the defaults, who can change them, and what it costs to opt out.
Explore more from Popular AI:
Start here | Local AI | Fixes & guides | Builds & gear | AI briefing